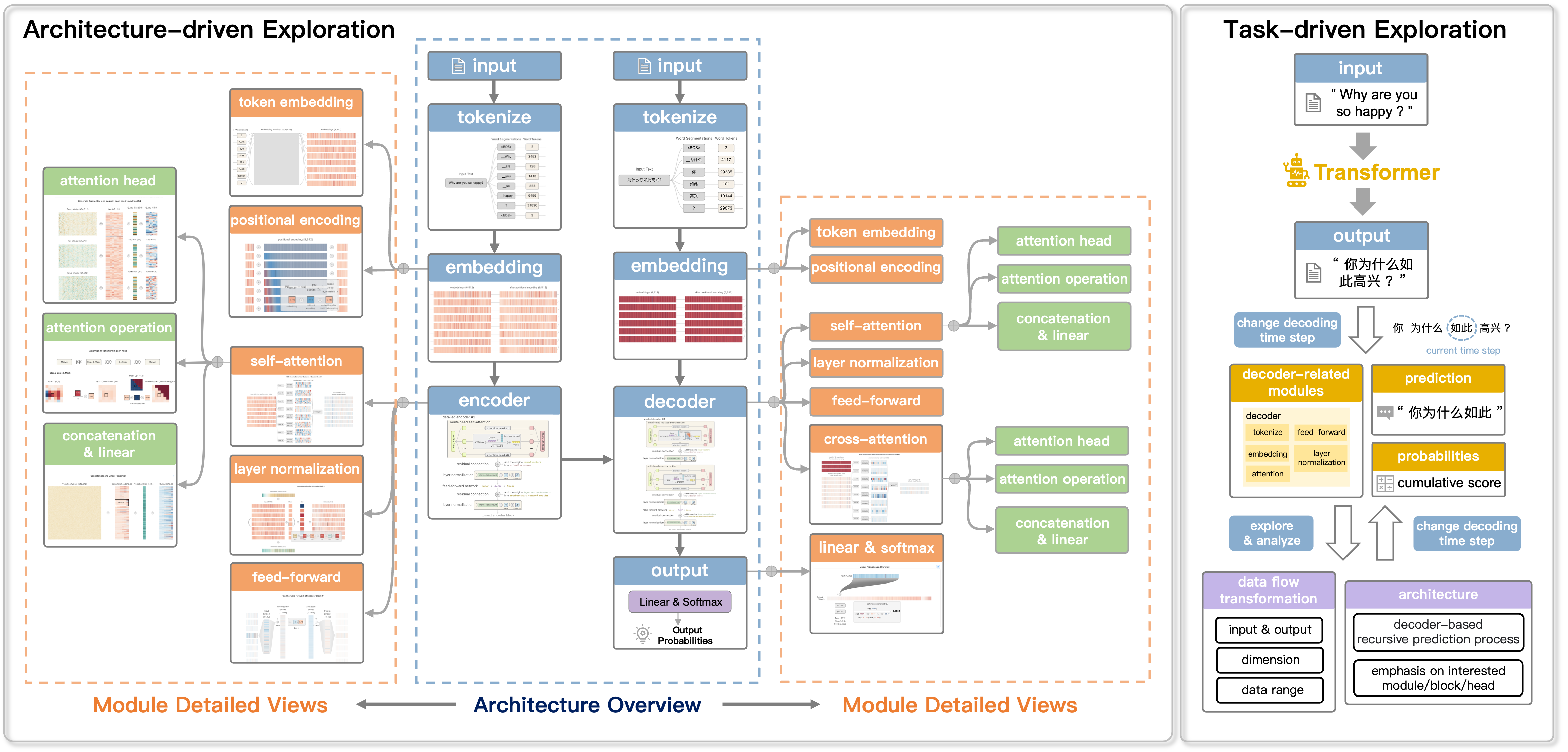
What is Transformer?
Transformer has emerged as a prominent and widely-used tool in natural
language processing (NLP) due to its
exceptional performance, first proposed by Google in 2017. Transformers serve as key kernels supporting
the most popular large language models.
Structurally, the Transformer belongs to the encoder-decoder
design.
The encoder block features a multi-head self-attention mechanism and
a positional feed-forward network,
while the decoder block includes a multi-head cross-attention
mechanism.
These elements are linked by a combination of two operations: residual
connection and layer normalization.
In machine translation tasks, the input text is expressed by embedding and positional encoding to obtain
numerical representations of word embedding.
![]()